
🚀 Optimizing Database Queries in Wirechat Package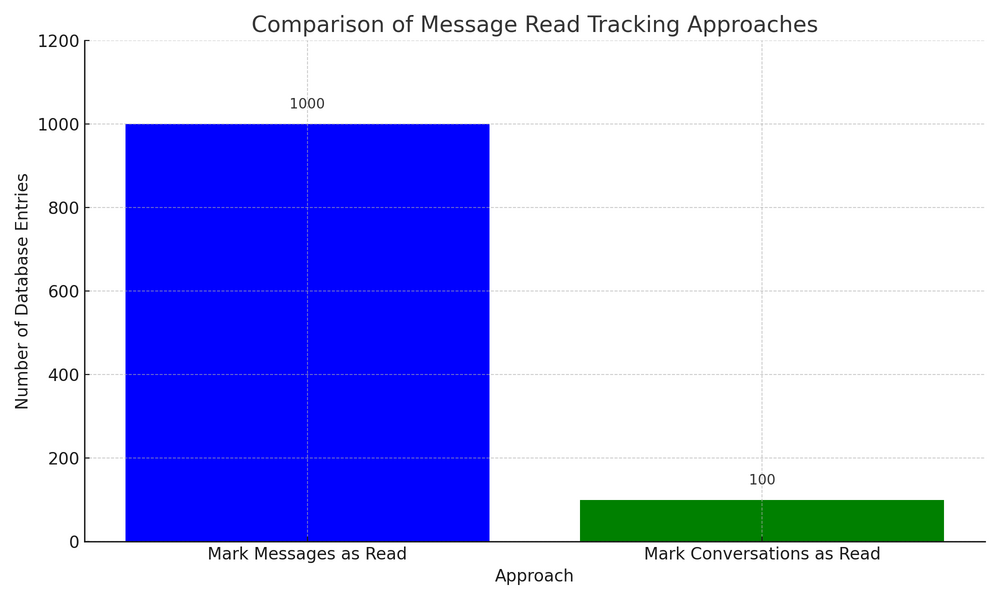
I recently addressed a scalability issue . Initially, I tracked each message's read status in the reads table, which became inefficient as the database grew rapidly. Here’s how I optimized it:
✨ Shifted Focus: Instead of tracking reads per message, I now mark entire conversations as read for users based on timestamps in the reads table.
🛠️ Improvements:
1. Replaced message-level reads: Transitioned to marking conversations as read with a timestamp.
2. Enhanced unread tracking: Compared the conversation's last read timestamp with new messages to identify unread ones.
Results:
1. Reduced database load: Fewer rows in the reads table improve performance.
2. Cleaner logic: Reused methods for better maintainability.
I just implemented this and will test its scalability :) . If it holds up, I’ll fully adopt this approach!
Back